


Data Integrity
Data integrity issues are often challenging for users to detect. They may be rendered as valid characters or blanks, and the integrity standards can vary depending on the type of data—character, numeric, or date. Knowing how to search for them can require a high degree of knowledge that may be beyond the scope of the user. However, due diligence with respect to the data's integrity should be tested before audit procedures are begun.
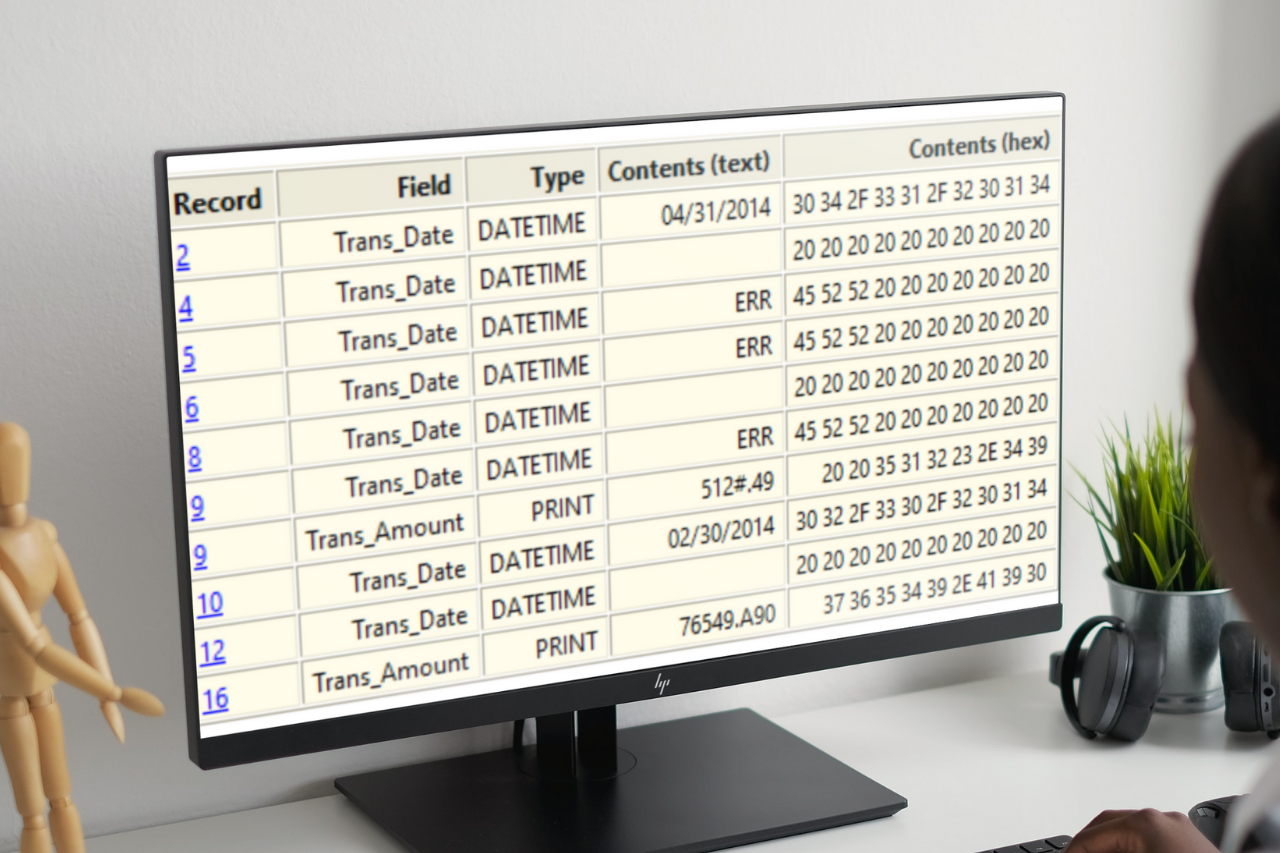
The Verify command can search the entire data file (or specific fields) to identify integrity issues. The output will display the underlying text as well as the underlying hexadecimal characters. This can support the user when the data provider requests proof that the data has been corrupted.
In this example, date and numeric fields are tested, and the exceptions are detailed in the Log. Invalid date content, blank dates, and invalid characters in the numeric (PRINT) fields are detected:
Statistics on Dates
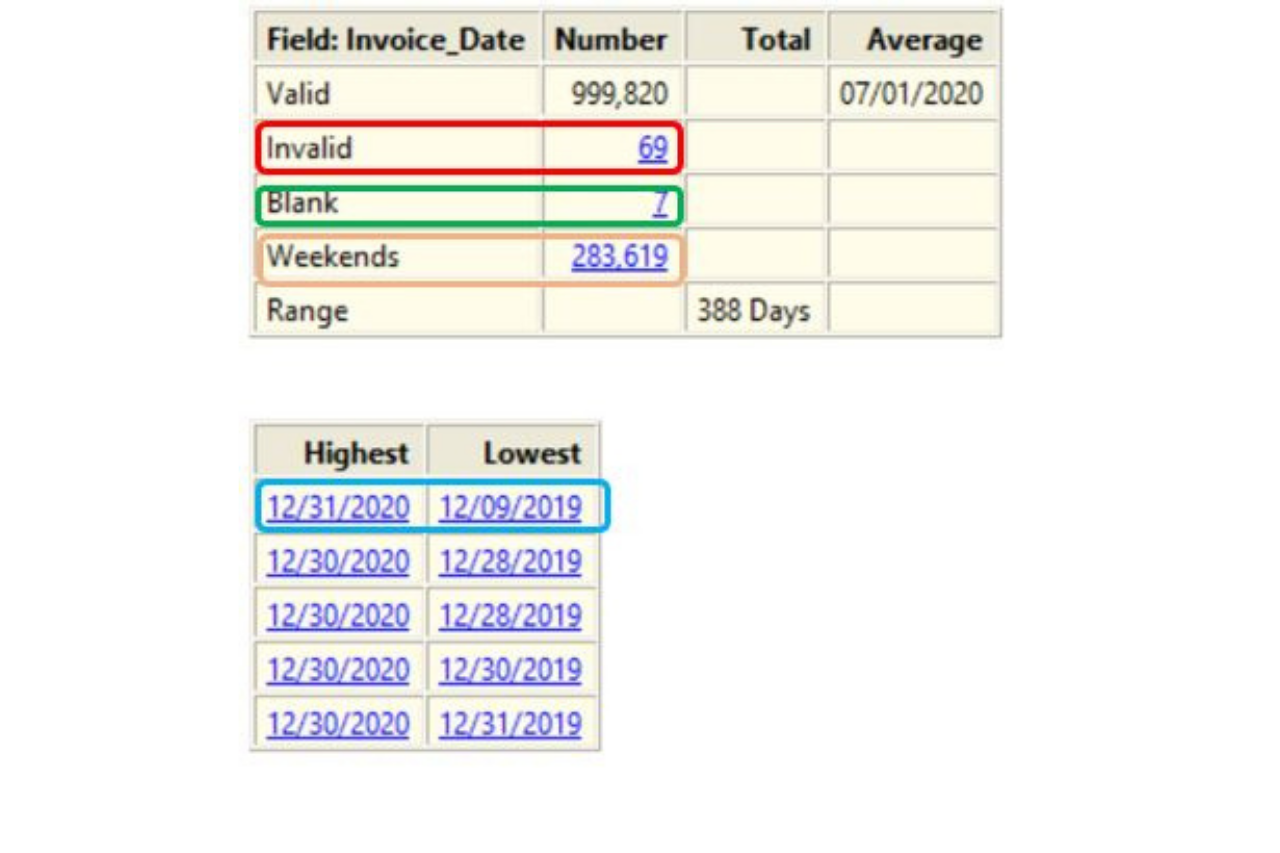
The Statistics command can be run against date fields. In just one pass, Arbutus will identify:
• Blank dates
• Invalid dates (content is non-blank and not a date)
• Weekend dates
• Oldest and newest dates
• Range
Summarize with Statistics
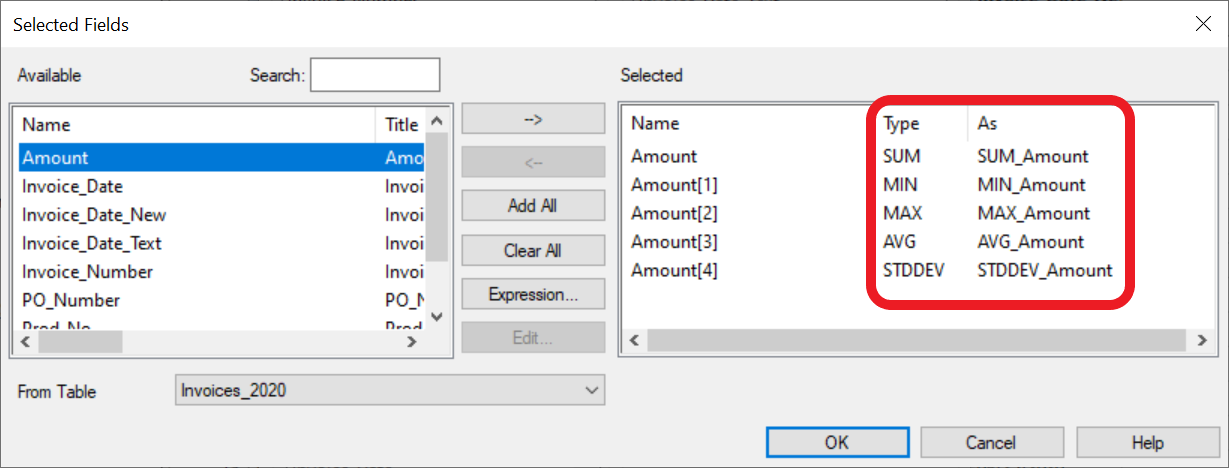
👈 Select the same field multiple times and click on the Type to change it to the desired statistic:
The enhanced Summarize command can calculate the following values for numeric fields selected in the "Fields to process" list:
- First - the first value encountered based upon the data being ordered upon the key fields
- Last - the last value encountered based upon the data being ordered upon the key fields
- Sum - the total of the selected numeric column
- Avg - the average (or mean)
- Min - the minimum value
- Max - the maximum value
- StdDev - the standard deviation
- Median - the median
- Mode - the mode
- Q1 - the first quartile
- Q3 - the third quartile
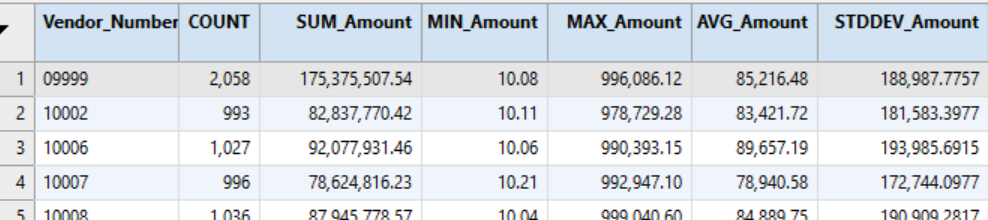
This can provide useful profiles on payments to vendors by creating those statistics for each vendor's set of invoices. The output can also be used to identify outliers by calculating the 2 standard deviations threshold for each vendor rather than the population as a whole. The population file can then be joined to this file to capture each vendor's threshold. A filter will then identify the payments for each vendor that are greater than the thresholds.
Duplicates, True & Fuzzy
Finding duplicates appears, on the face of it, to be a simple, binary task: either two things are the same or they aren't. However, for auditors and other analysts, there exists a third, grey area—two or more items may resemble each other to a great degree without being exact duplicates.
Examples of fuzzy duplicate tests abound: Duplicate payments with same vendor, same amount, within x days of each other; addresses with one-character differences; payments within x days of each other for amounts within y dollars or euros; account numbers that may look the same but contain different characters, such as "A165" and "AI65".
Analysts deployed complex testing algorithms to identify such items in the past. However, the enhanced Duplicates command offers a simple solution that new users can execute from day one.
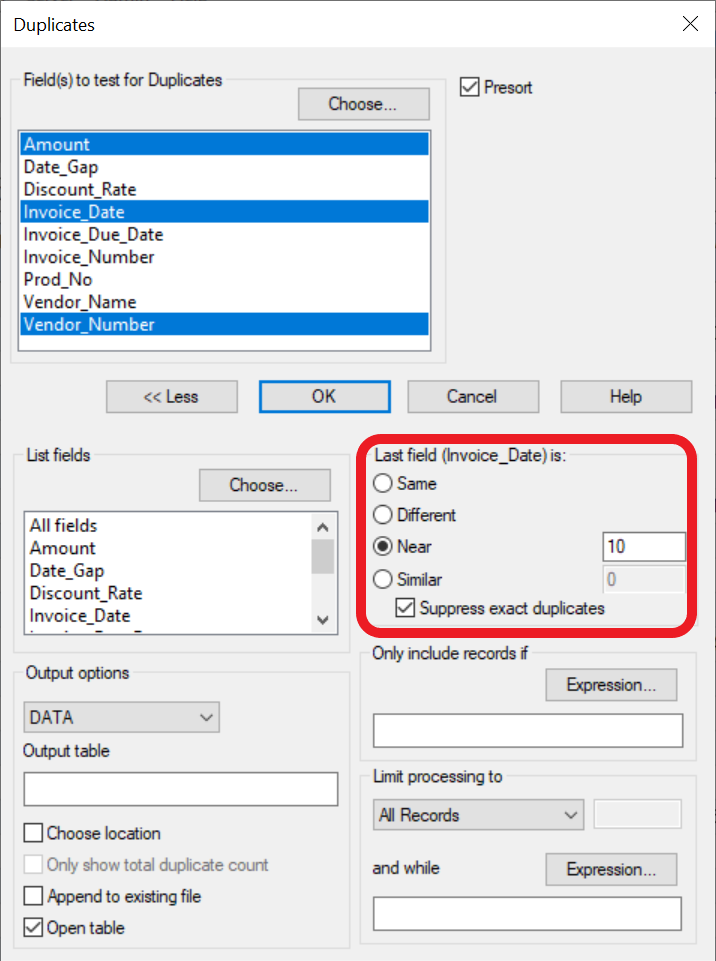
The area in the red rectangle below provides the various options for enhanced duplicate detection. In this case, the search is for same Vendor Number, same Amount, and Invoice Dates within 10 days of each other, with exact duplicates excluded from the output.
The "Near" parameter is expressed in the units of the last field selected. If the final field had been the invoice amount, the search would have been for the number of currency units difference.
The "Similar" parameter would allow the search for items that resemble each other such as the "A165" and "AI65" previously mentioned. The parameter value would indicate how many similar characters would be searched for.
On-Demand Webinars
Arbutus, in partnership with AuditNet, presents series of engaging webinars with live Q&A. Insightful demonstrations and informative content presented by Arbutus Customers, Consultants and Data Analytics subject matter experts.
.png)
Arbutus Technical Insights
Explore more of our Technical Resources
