

.webp?width=296&height=131&name=arbutus_AI-Powered-Advanced-Analytics%20(1).webp)

Data Quality Matters
While everyone has heard of the concept "Garbage in, Garbage out" (GIGO), for most of us this is just an accepted, but abstract, concept. Today we'll explore Data Quality (DQ) more closely, and show how to minimize GIGO.
The Problem
In an ideal world, every system would have the highest levels of built-in DQ checks, but sadly this is almost never the case. While, there are a number of reasons for this, here are just a few:
With the explosion of data, awareness of the importance of DQ is increasing. What this often means is that the older the system is the lower the quality of the data checks. Legacy systems and environments are particularly susceptible. This is because not only was there a lower importance placed on DQ historically, but there might have been limited resources/computing power to implement appropriately comprehensive tests. Even where you are dealing a modern system, it's hard to think of everything. Think of a simple field like a date. It's easy to think of problems such as very old dates (did they really become a customer in 1919?), dates in the future, or just plain invalid dates ("Unknown", or the ubiquitous " / / "). There are a variety of other situations that aren't hard to think of, but may be overlooked. What about sequencing, like it was shipped before it was ordered, and similar situations? What about date formatting (D/M/Y vs M/D/Y vs, Y/M/D), or just different ways of typing it (slashes vs. dots vs. dashes)? Date pickers are a modern approach to this issue, but may not be available for legacy environments. Harder issues may be weekends, statutory holidays and the like, when the business is closed.

The Implications
Here's where GIGO rears its head. Bad data can easily affect the results you find, or the quality of the decisions you make, based on that data. As mentioned, it is very challenging to anticipate in advance exactly what errors will subsequently affect your analyses and decision making. This is particularly true in the dynamic age of big data we find ourselves in today. Perhaps tomorrow's work is based on the day of the week, or the time of day. This data may not have been tested in the past, because this is a new analysis. As an analyst starts the work they might think to test this themselves (if they have the right tools), but if they just trust the data and it's wrong, the results could be compromised.
Data Quality and it's Importance
Dates are but one example, but they do show the level that one can investigate DQ. Many data elements in your systems can have the same depth of DQ issues, and virtually every data element offers some opportunity for DQ improvement. It is also important to remember that your uses of your data change over time. What was relatively unimportant at the time a system was implemented can become crucial to your current analyses. When a system was implemented it may not have mattered that a transaction was booked on a day the business was closed, but now it's crucial to identifying a fraud.
Being aware of this phenomenon is one step towards the awareness of DQ's importance.
Finally, DQ can be expensive. Not only is there a cost associated with thinking about (and implementing) DQ, but there can be a significant cost attached to the resources required to enforce it. If a production process runs twice as slowly as a result of DQ tests, there could be significant implications for the business.
No business wants to waste money, and even DQ becomes a cost/benefit analysis. The problem with this is that the subsequent costs and benefits associated with future use of the data are unknown at the time the implementation decisions are being made.
One Approach-Testing After the fact
Given that enterprise data encompasses a variety of systems, built in different environments, at different times, and by different personnel, it might be a bit naïve to expect that every system has the appropriate level of base DQ. Instead, a powerful approach can be to test the data after the fact.
Testing after the fact can give you the benefit of hindsight. Rather than anticipating every potential use for every piece of data when a system is implemented, you can design and run new DQ tests now, and identify the data quality issues that affect your current analyses. Further, as your analysis needs change (and therefore your DQ expectations), you can verify these new requirements, without necessarily taking the costly step of updating the source software.
The response to discovered issues will vary, depending on severity. You may choose to ignore the problem, fix the data, or even update the source system to prevent the error from being accepted. Each type of error has a unique impact on your analyses, but awareness that an issue exists is the first step.
DQ Implementation
A properly implemented DQ program would:
- Proactively monitor data and report data quality issues (with appropriate frequency) for all enterprise applications in order to ensure critical data for management information purposes is always clean
- Be easily updated to meet the changing needs of the organization
- Achieve better information systems derived from improved data quality detection and reporting
- Achieve better business decisions and outcomes from the use of trusted and accurate enterprise data
While it may not be your job to monitor data quality, it may be your job to report on the state of DQ. With the correct tools you can test virtually every data field, and ensure that data quality issues are identified and addressed in a timely manner. By ensuring that the data is clean, and is kept clean, you minimize GIGO and help ensure that everyone can trust your data and its accuracy.
Where is the Error?
When testing DQ you often have two major sources: a data repository, like a data warehouse (DW) or data mart, or the source data itself. Both are different, and both are important to check. The DW should obviously be 'clean', but being clean doesn't mean it's right. Errors in loading the repository (ETL) can easily mask source data errors or issues, and result in incorrect DW contents. Only by looking at the source data can you know your data quality.
A simple explanatory example might help. A DW table might contain a field sex, relating to customers, which is created from an external system. The logic to load the DW field might be as simple as if source:sex="M" then DW:gender="M" otherwise DW:gender="F". This guarantees apparently clean data in the DW, but mis-represents any errors as female, which could have serious implications on your use of the DW. Whether it was unknown at the time of entry, or simply a typo, you never know what's in the source system unless you look.
Looking at the source data, it may just be a single character field that is expected to contain "M" or "F". But the source system may not validate this field, so it may contain "m", "?", "U" or even a type like "L". Identifying the quality of the source system is fundamental to any DQ exercise.
Reading the Data
Source data is traditionally difficult to access, which is one of the reasons warehouses evolved. That is why Arbutus' unique capabilities are so important. Arbutus offers a suite of products that can access all of your source data, in place, regardless of the age of the system or the complexity of the data.
Arbutus technologies are not only compatible with any relational database, but more importantly, our native mainframe application allows access to any of the legacy data on your corporate mainframe as well. This includes VSAM, IMS, DB2, ADABAS and even VSAM and flat files with variable record lengths and multiple record types!
Arbutus Implementation
Once written, you can regularly schedule data quality testing jobs that perform a thorough check of your legacy data on a timely basis. They can report data anomalies and errors for review and correction; this will prevent them from propagating throughout your systems. Most importantly, all of this can be realized with no ETL programming. The process is all point-and-click and typically takes just minutes to implement.
-
Data Quality Definition
Simply put, a data quality (DQ) error implies that the item doesn't match the explicit or implicit metadata definition. An example of an explicit definition might be that the data is numeric, whereas an implicit definition example is that the employee age field shouldn't be less than 16 or greater than 70. Either type of problem could have significant implications.
-
Data Quality Categories
A commonly accepted IT framework for DQ errors is:
While accurate, you may find these categories to be a little abstract. Instead, you could consider the following data categories:
• Invalid
• Improper
• Incomplete
• Inconsistent -
Data Quality Examples
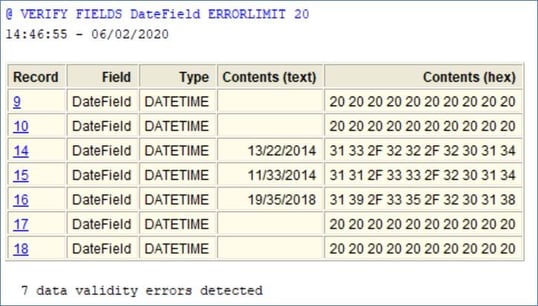
Invalid data doesn't match the defined field type definition. If the data is supposed to be numeric, but actually contains "UNKNOWN" then the data is invalid. In the case below, there is invalid data in DateField; there are blanks and nonsense dates that have been detected.
Improper data is technically valid, but doesn't match the expected business rules. The field may be blank, improperly formatted (like a phone number), non-unique, improperly sorted, contain characters that while technically valid are inappropriate for the field (like 12345 for an address), or may be too small or large (like ages)
Incomplete data is all technically valid, but violates some higher-level business rule. One example of incomplete data would be sequential invoice or cheque numbers. There may be an expectation that the company's invoice numbers form a continuous set, with no gaps.
Another common example of incomplete data involves the matching of key values to other tables. For example, every customer transaction should have a customer number that is also represented in the customer master file. Identifying errors of this type will not only catch missing customer master records, but also DQ issues in the transaction or master file keys themselves.
Inconsistent data involves data that is internally inconsistent. This might be as simple as a table that contains quantity, price and value fields, where the value is not equal to the quantity times price. Most other inconsistence examples involve matching data (other than keys) between tables. The same value might be represented in two or more tables, and be different in one. Or the total of the customer transactions should total the customer master YTD total, but doesn't.
-
Data Quality Discovery
JUST DO IT
Whatever categories you prefer, Arbutus allows you to fully test all these characteristics, and to automatically schedule their ongoing testing. With a proper process, over time, not only will you consistently achieve more trusted and accurate data, inevitably you will facilitate better overall information systems as result of your ongoing and timely findings.
DQ DISCOVERY
One last area worth mention is that while some organizations have formalized metadata for all data elements, many have not. If you have formalized rules, then the testing can almost be a check-list. For the majority of organizations that don't have complete formalized metadata, DQ can involve an interactive process to "discover" the rules. Even if you have formalized rules, the discovery process can be very valuable, as very few instances of metadata are complete and current. When discovering rules, you just look at the data and notice issues, but there are organized approaches that often yield results quickly. These include:
Outliers: If you use commands like Classify, you can quickly identify the common values in the table. More importantly though, you can identify the least common values. These can be places where errors hide.
Sorting: Sorting is very easy in Arbutus, just a right-click away. Once done, you can look at the highest and lowest values for each column. Again, data at the extremes is more likely to be incorrect.
Formatting: Where data is expected to have a known format e.g., North American phone numbers as "(999) 999-9999", you can easily test the data with the Format function. Just add a column to your table that is "Format(fieldname)". You can then Classify on this field to find the outliers based on the format of each data element. As with the other techniques, the least common formatting is either wrong by definition, or more likely to harbor errors.
An important part of any discovery process is the feedback loop into the metadata. If you find a problem, then by definition it violates some business rule. You will probably want to add this to your automated testing, to catch it in the future. It is important to ensure that all such rules are formally articulated, so that as you enhance your DQ infrastructure you also start to learn about your data.
Analytics By Business Process
Learn more about various analytics tests to meet business needs.
Analytics By Business Process

Arbutus Technical Insights
Explore more of our Technical Resources
