

.webp?width=296&height=131&name=arbutus_AI-Powered-Advanced-Analytics%20(1).webp)

Risk-Scoring For Journal Entries Using Data Analytics
Try Now & See it For Yourself.
What Are Journal Entries?
Journal entries are simply the debit and credit transactions that are applied to general ledger accounts. These entries are, in most organizations, automatically posted by one or more ERPs. Manual journal entries can also be posted by parties with the appropriate duties. The key fields that occur in journal entries are the amount, the GL account, the posting date, the DR/CR indicator, reference numbers, cost center, the user, and the creation date.
The Impact of Fraud
The ACFE conducts an annual survey of occupational fraud schemes. Although financial statement frauds are relatively low in number, the average financial statement fraud is nearly one million dollars, quite a bit more than the other categories.

ACFE "Report to the Nations: Global Study on Fraud and Abuse 2020"
In this example, we've created four tests and applied a binary risk score if the journal entry meets the test. Each journal entry's score is then summed for an overall risk score. The highest-scoring entries should be reviewed first, followed by the next-highest, and so on. You can run several analytics on the high-scoring items, such as aggregating them by the person making the entry, the time period, the and the GL account. You can create a binary score using your data analysis application's conditional computed field functionality.

figure2: Risk-Scoring example






Summing the Scores
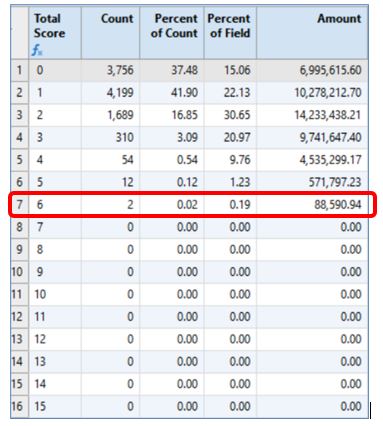
Once all the tests have been created, create another field to sum the scores for each posting. You can then run additional analytics to identify possible trends or commonalities. For example, you may want to use the Stratify command to see the frequency distribution of the total scores.
In this example, we can see that two journal entries had the highest score of 6. Their total materiality is nearly $89,000 or .19% of the total population materiality.
Other analytics to consider are frequency distributions by user, GL account, and other characteristics. The Classify command can produce the user distribution with the scores in descending order. This can be done by selecting the "By Size" and "All items" parameters in the Classify command dialog:

