



Normalize Address and Detect Duplicates
What is the ADDR.TXT File?
This is a simple text file with two columns of words. The words on the left are those that can be found in most addresses, including abbreviations. The words on the right are the result of the transformation by SortNormalize(). For example, the following instances of "avenue" are all transformed to the text on the right. As well, this will remove the "noise" words that have no partner in the list, such as "THE" and "OF".

This is a plain text file, so users can easily update it by adding another line containing a new replacement pair. This file can be referenced in the computed field expression without a full path only if it is located in the Arbutus project folder. If the text file is located in other locations, you must specify the full path.
Exact Matches - Single File Testing
Create a computed field (Edit >> Table Layout >> Add a New Expression) in your file that will transform the address using the SortNormalize function. The expression should reference the address substitution file ADDR.txt.
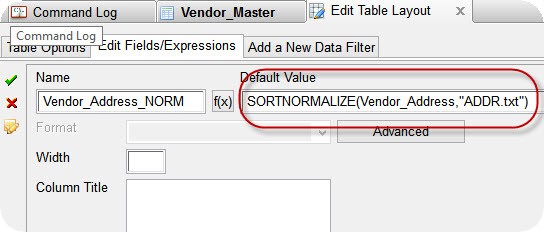
Although it is not necessary, you can add the computed field to the View next to the original address field for comparison.
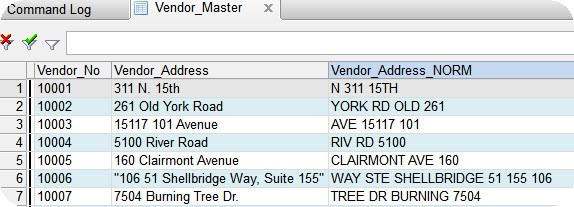
Run the Duplicates command using the new computed field and the zip code as the key fields. Including the zip code helps reduce false positives by ensuring that two identical addresses in different zip codes will not be included in the output. In the "List fields" area below, select the original address field and any other fields you would like in your output.
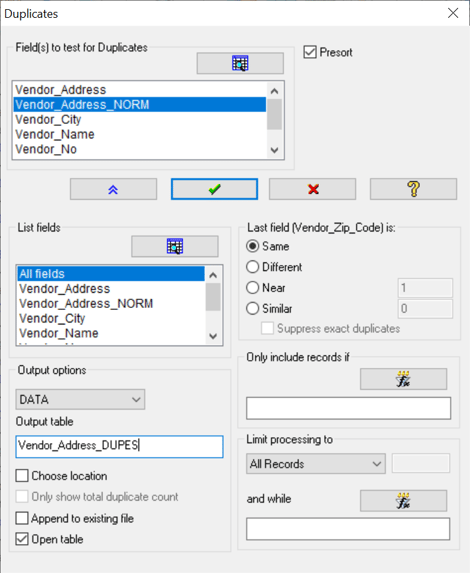
Name the output file and click "OK". The result shows all normalized matches that are identical. Note how different the original addresses are from each other, and how they are identical when normalized.
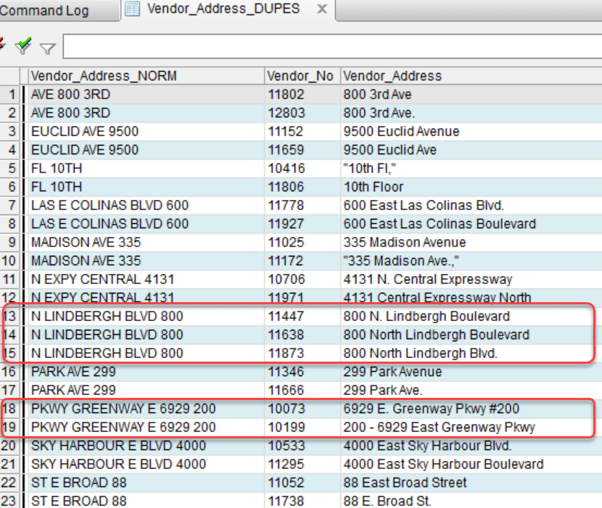
Exact Matches - Multiple File Testing
- Create the computed fields in each of the two files.
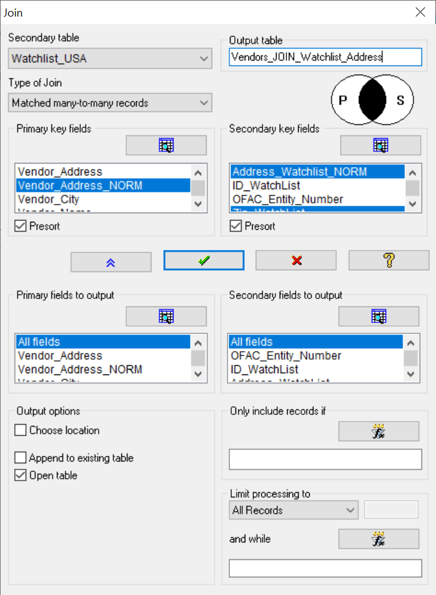
- Create a Matched Many-to-Many Join between the two files, using the two new computed fields as the key fields as well as the zip codes. (It does not matter which file is the Primary or Secondary for our purposes.)
- Select any other fields you need in your output from the "Primary fields to output" and "Secondary fields to output" lists
- Name the output file and click "OK"
- The result will show all normalized matches that are identical; the possible matches are side-by-side. It is possible for the same vendor address to match to multiple watchlist addresses and vice-versa. Vendor 10088 matches to three watchlist addresses

Analytics By Business Process
Learn more about various analytics tests to meet business needs.
Analytics By Business Process

